EditP23
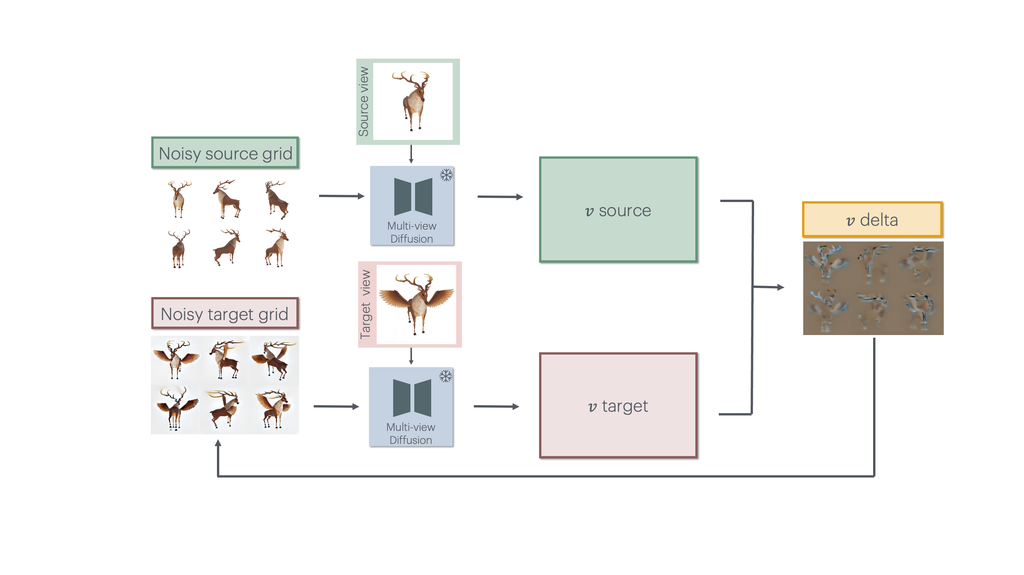
3D Editing via Propagation of Image Prompts to Multi-View
We propagate user-provided, single-view 2D edits to the multi-view representation of a 3D asset. This enables fast, mask-free, high-fidelity, and consistent 3D editing with intuitive control.

Source view

Edited view

Source view

Edited view

Source view

Edited view

Source view

Edited view

Source view

Edited view